\(\Sigma\) is estimated with two parameters, \(\phi\) and \(\sigma^2\)
11.2 Spatial autocorrelation
The Gaussian (most commonly modeled) spatial correlation structure quantifies the correlation between (the residuals) of two points, assuming that it onnly depends on their distance:
\[\text{Cor}(\epsilon_{i,j}, \epsilon_{i,j}) = \exp \left(- \left({r_{i,j} \over \lambda}\right)^2\right) \] Where \(r_{ij} = ||{x_i,y_i}|| - ||{x_j,y_j}||\), i.e. the distance between the two points, and \(\lambda\) is a single parameter that quantifies the scale of spatial correlation. Note that:
at \(r = 0\), the correlation is 1
as \(r \to \infty\), the correlation goes to 0
at \(r = \lambda\), the correlation is \(1/e\)
The last fact is a useful way to interpret \(\lambda\) … as long as points are within distance \(\lambda\) of each other, they will be affecting each importantly.
As with serial autocorrelation (in time), the biggest risk of not accounting for spatial correlations is that you might detect spurious results, i.e. p-values will be artificially too low.
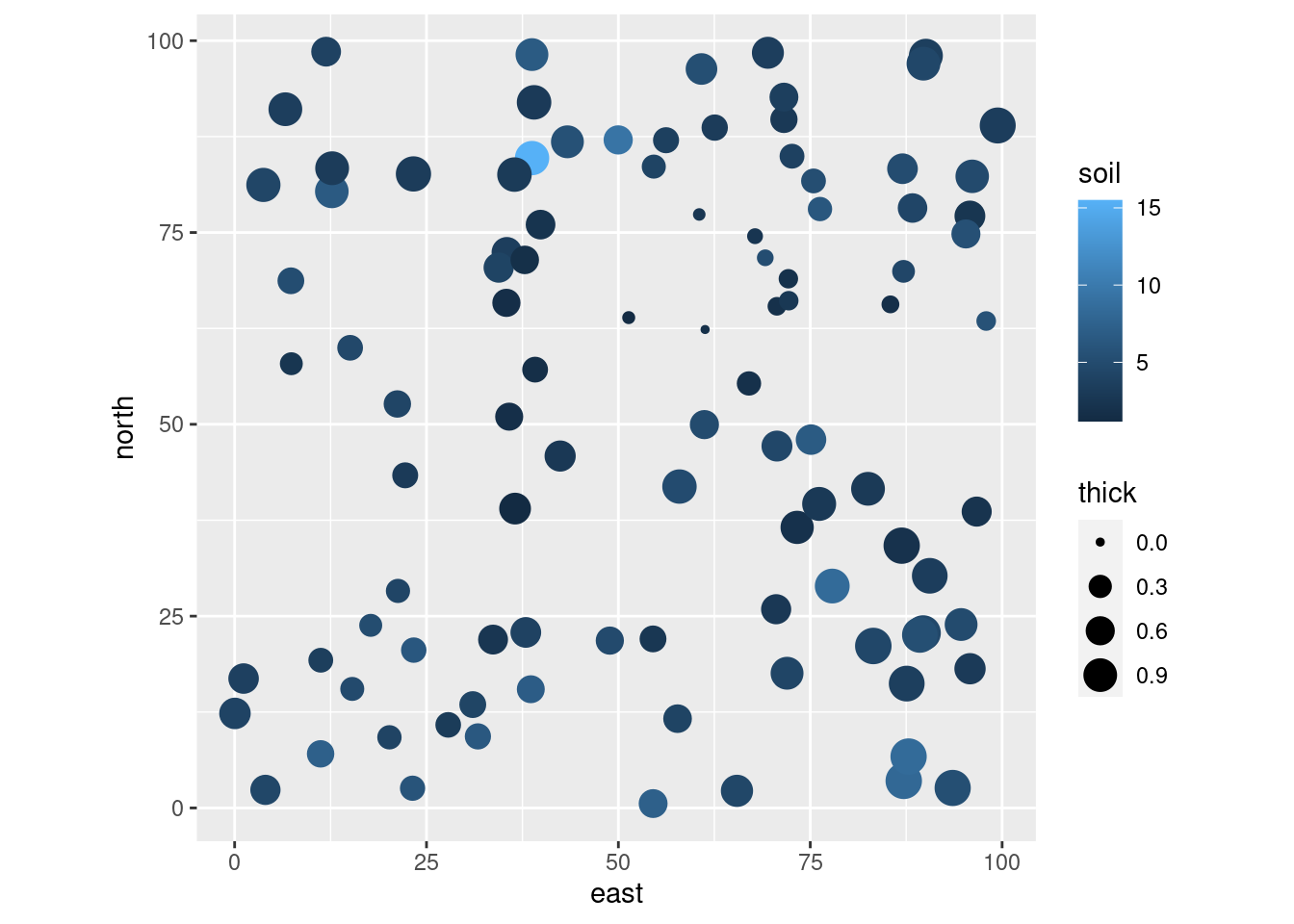
11.2.1 Example: Soil Quality Data
The gls and nlme functions in R can fit this (and a few other) spatial correlation structures in a linear modeling framework. As an example, here is one I found online which measures soil thickness as a function of quality at different locations
A straightworward linear model suggests that quality (which is measured at the surface) is a significant predictor of thickness (which is harder to measure):
Read about how this works in the ?corGauss help file and see a list of other correlation structures in nlme in the ?corClasses help file
11.2.4 Same Model with lme
The lme syntax is nearly identical. But: - because because it is a more general (and powerful) function, it is a bit more sluggish. - because it is designed for mixed effects models, it DEMANDS a “random effect”, which in this case is th column of dummy 1’s
require(plyr)soil.lme<-lme(fixed =thick~soil, data =mutate(spdata, dummy =1), correlation =corGaus(1,~east+north), random =~1|dummy, method ="ML")summary(soil.lme)
Linear mixed-effects model fit by maximum likelihood
Data: mutate(spdata, dummy = 1)
AIC BIC logLik
-343.0238 -329.998 176.5119
Random effects:
Formula: ~1 | dummy
(Intercept) Residual
StdDev: 9.729671e-06 0.2852258
Correlation Structure: Gaussian spatial correlation
Formula: ~east + north | dummy
Parameter estimate(s):
range
19.87889
Fixed effects: thick ~ soil
Value Std.Error DF t-value p-value
(Intercept) 0.6409115 0.07583080 98 8.451862 0.0000
soil -0.0000163 0.00006036 98 -0.270433 0.7874
Correlation:
(Intr)
soil -0.039
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-2.24693213 -0.80586477 -0.02488151 0.81001862 1.66996856
Number of Observations: 100
Number of Groups: 1
But the conclusions are the same.
11.2.5 Challenges
Auto-correlation structures are most easily defined for Gaussian models.
For glm’s it is much more difficult to separate a modeled term from a residual term
In general, these models can take a long time to fit - because inverting large matrices
Combining both temporal and spatial autocorrelation is very difficult / not possible in these frameworks
Bayesian MCMC can fit anything … but can take a long time to run.
Probably the biggest, most powerful “gun” in the generalized / correlated / nested / mixed / additive modeling universe is: INLA (see: http://www.r-inla.org/) (integrated nested Laplace approximations).
11.3 Exercise: Ozone
Load the Ozone data in the plyr package This is a 24x24x72 numeric array which contains monthly ozone averages on a coarse (24 x 24 grid) covering Central America, from Jan 1995 to Dec 2000. Below, for example, is a plot of ozone concentrations on August 1995:
lat long time value
1 -21.2 -113.8 1 260
2 -18.7 -113.8 1 258
3 -16.2 -113.8 1 258
4 -13.7 -113.8 1 254
5 -11.2 -113.8 1 252
6 -8.7 -113.8 1 252
To add the “correct” month and year to this data frame:
O3.df<-mutate(O3.df, year =1995+floor((time-1)/12), month =time-(floor((time-1)/12)*12))
An important additional tweak - we don’t actually want to do spatial analysis in latitude/longitude. We need to convert to a consistent unit (e.g. in km). This is a fairly large area, and the distortion of the earth might distort any projection, but this seems like a good one: https://epsg.io/5367. We use our spatial data skills for earlier chapters:
For the analysis below, pick any month and year combination.
Map the ozone concentration for that month/year combination.
Perform a straightforward linear regression of ozone concentrations against East and North. Does there appear to be a East-West or North-South trend in either of those directions?
Estimate the spatial scale of autocorrelation in ozone concentrations.
Does taking that correlation into account change your conclusions about longitudinal or latitudinal trends in ozone concentration?
Bonus Problem: Write a function that performs this analysis for any year month combination. Perform it across all months. Are there any consistent annual patterns in (a) spatial scale of correlation and (b) longitudinal and latitudinal trends in ozone?